Appearance
阻塞/非阻塞/多路复用 I/O 演进详解
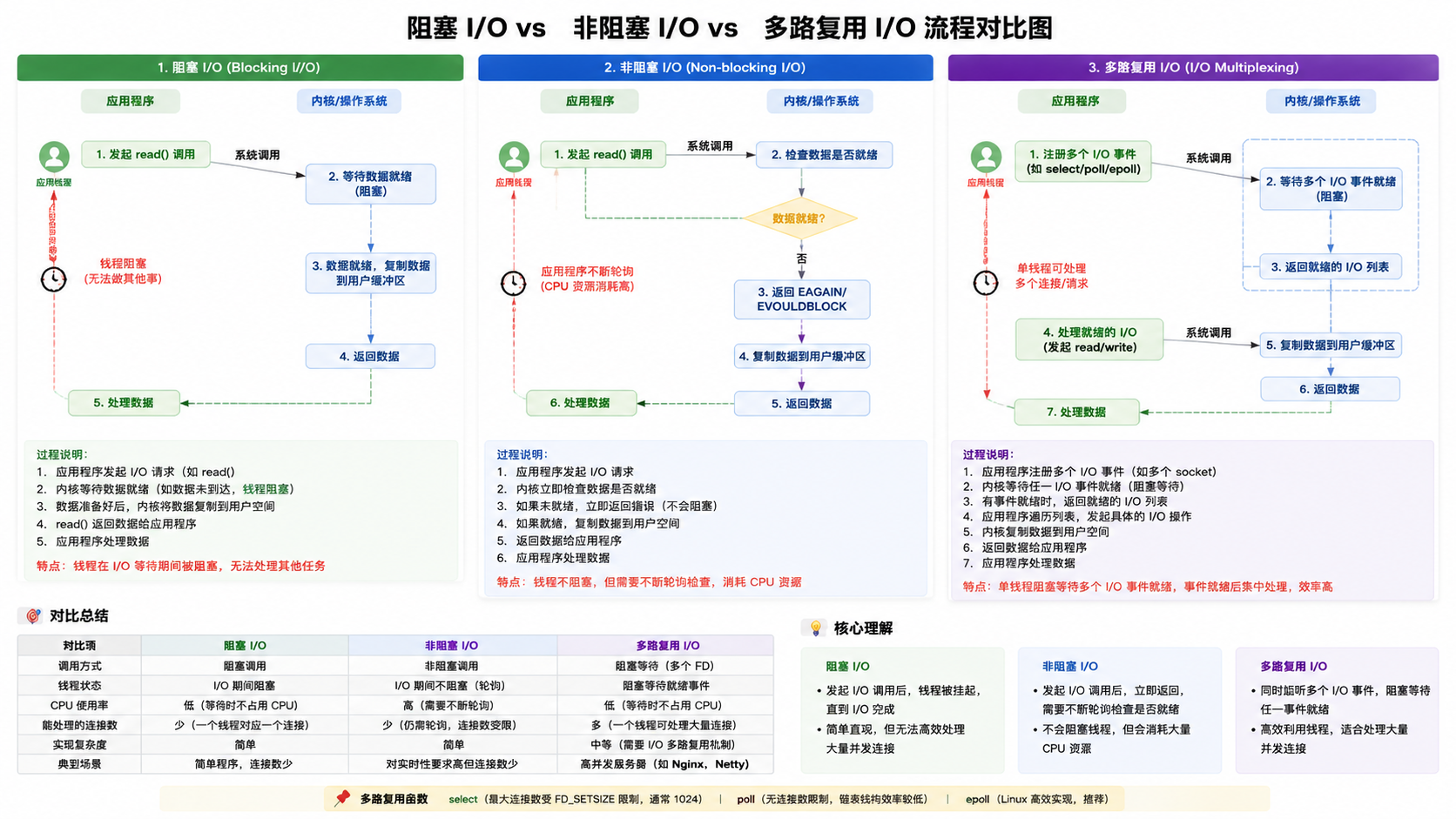
一、先给一个对比总览
| 模型 | 核心特点 | 比喻 | 适用场景 |
|---|---|---|---|
| 阻塞 I/O | 线程挂起等待完成 | 去食堂排队,干等着 | 连接少、简单直接 |
| 非阻塞 I/O | 轮询检查,立即返回 | 时不时去问"好了没" | 需要快速响应,但轮询成本高 |
| 多路复用 I/O | 一个线程监控多个fd | 叫号系统,坐着等叫号 | 高并发,连接多但活跃少 |
二、演进之路(面试核心逻辑)
阻塞 I/O 的问题 → 非阻塞 I/O 的尝试 → 多路复用 I/O 的成熟方案
↓ ↓ ↓
一个连接一个线程 用户态轮询CPU空转 内核通知+单线程管理多连接
线程资源耗尽 效率极低 真正的高效三、详细拆解(带代码逻辑)
1️⃣ 阻塞 I/O(Blocking I/O)
c
// 最传统的 socket 编程
sockfd = socket(AF_INET, SOCK_STREAM, 0);
connect(sockfd, ...); // 阻塞,直到连接建立
recv(sockfd, buffer, ...); // 阻塞,直到有数据到来问题暴露:
- 10,000 连接 → 10,000 个线程
- 线程上下文切换开销巨大
- 大部分线程其实在等待(阻塞),不干活
┌─────────────────────────────────────┐
│ Thread 1 ──[阻塞等待数据]──× │
│ Thread 2 ──[阻塞等待数据]──× │
│ Thread 3 ──[阻塞等待数据]──× │ ← 大量线程阻塞,资源浪费
│ ... │
└─────────────────────────────────────┘2️⃣ 非阻塞 I/O(Non-blocking I/O)
c
// 设置非阻塞
fcntl(sockfd, F_SETFL, O_NONBLOCK);
// 轮询方式
while (1) {
n = recv(sockfd, buffer, ...); // 立即返回,无论有无数据
if (n > 0) {
// 处理数据
} else if (n == -1 && errno == EAGAIN) {
// 没数据,继续轮询... (CPU空转!)
}
}进步与缺陷:
| 进步 | 缺陷 |
|---|---|
| 一个线程可以处理多个连接 | 用户态轮询 = 大量无效系统调用 |
| 线程不会阻塞 | CPU 飙高,实际没做有用功 |
┌─────────────────────────────────────┐
│ 单次循环: 系统调用recv × 10000次 │
│ 实际有数据的: 可能只有 10 个 │
│ → 9990 次系统调用是浪费的! │
└─────────────────────────────────────┘3️⃣ 多路复用 I/O(I/O Multiplexing)⭐重点
核心思想: 让内核来监控多个 fd,有数据时通知我,而不是我挨个去问。
c
// select / poll / epoll 本质是同一类思路
int epollfd = epoll_create1(0);
// 1. 注册要监控的fd
epoll_ctl(epollfd, EPOLL_CTL_ADD, conn_fd, &ev);
// 2. 阻塞等待内核通知(不是等待I/O,是等待"就绪通知")
epoll_wait(epollfd, events, maxevents, timeout);
// 3. 只处理"有数据"的连接(确定有数据,不会阻塞)
for (i = 0; i < nfds; i++) {
recv(events[i].data.fd, buffer, ...); // 这里大概率成功
}关键理解:
┌─────────────────────────────────────────┐
│ epoll_wait 阻塞的是:"哪个fd就绪了?" │
│ 不是:"从fd读数据"(那是I/O阻塞) │
│ │
│ 内核帮你轮询 → 有结果才唤醒你 │
│ 没有CPU空转,没有无效系统调用 │
└─────────────────────────────────────────┘四、面试黄金回答框架(3分钟版)
面试官:说一下阻塞、非阻塞、多路复用的区别?
回答结构:"问题-方案-演进"
"这三个其实是 I/O 模型逐步演进的三个阶段,解决的是高并发下如何使用更少资源处理更多连接的问题。"
第一步:阻塞 I/O —— 最简单直接,一个连接一个线程。问题是连接数上来后线程资源扛不住,而且大量线程在阻塞等待,浪费严重。
第二步:非阻塞 I/O —— 改成非阻塞后,一个线程能轮询多个连接了。但问题是轮询发生在用户态,大量 recv 系统调用没数据就返回,CPU 空转,效率反而更低。
第三步:多路复用 I/O —— 本质是把"轮询谁就绪"这件事交给内核做。通过 select/poll/epoll,一次系统调用监控成千上万个 fd,只有真正有数据时才返回。这样既不会阻塞线程浪费资源,也不会有空轮询的开销。
最后总结: 现在高并发服务器基本都是多路复用 + 线程池的配合。比如 Redis 单线程 epoll,Nginx 多进程 epoll,都是这个模型。
五、深挖考点(面试官可能的追问)
| 追问 | 答法要点 |
|---|---|
| select/poll/epoll 区别? | select: fd数量有限(1024),每次要拷贝全部fd到内核;poll: 链表无数量限制,但仍要拷贝全部;epoll: 事件驱动,只关注活跃的fd,使用红黑树+就绪链表,O(1)获取事件 |
| epoll 的 ET 和 LT? | LT(水平触发):只要有数据就通知,容易实现但可能重复触发;ET(边缘触发):状态变化才通知,必须一次性读完,效率高但编程复杂 |
| 多路复用是阻塞还是非阻塞? | 都可以配合。epoll_wait 本身是阻塞的,但也可以设 timeout=0 变成非阻塞轮询。通常我们说"多路复用"默认指阻塞在多路复用调用上 |
| 为什么 Redis 是单线程还能这么快? | 纯内存操作 + 单线程避免锁 + IO多路复用处理并发连接 |
六、一句话记忆
阻塞是干等,非阻塞是傻问,多路复用是月初叫号。